Du glaubst, du kennst deinen Code. Du arbeitest jeden Tag damit, du weißt, wo die kritischen Stellen sind, du weißt, wo es wehtut. Oder?
Ich habe PhpCodeArcheology gebaut, weil ich genau das von mir selbst dachte - und dann festgestellt habe, dass Bauchgefühl und Realität erstaunlich oft auseinandergehen. Seitdem nutze ich das Tool täglich. Für zwei Dinge: Legacy-Projekte bewerten und refactoren. Und Neuentwicklungen von Tag 1 an im Blick behalten.
Legacy-Projekte: Wo liegen die Leichen?
Wenn ich ein Legacy-Projekt übernehme oder bewerte, verschaffe ich mir zuerst kursorisch einen Überblick über den Code. Ordnerstruktur, Namespaces, grobe Architektur, das Übliche. Dann installiere ich PhpCodeArcheology und lasse es laufen:
composer require --dev php-code-archeology/php-code-archeology
./vendor/bin/phpcodearcheologyMeine erste Anlaufstelle ist immer der Health Score. Eine Zahl von 0 bis 100, die mir sagt, wo ich stehe. Nicht als endgültiges Urteil, sondern als Startpunkt.
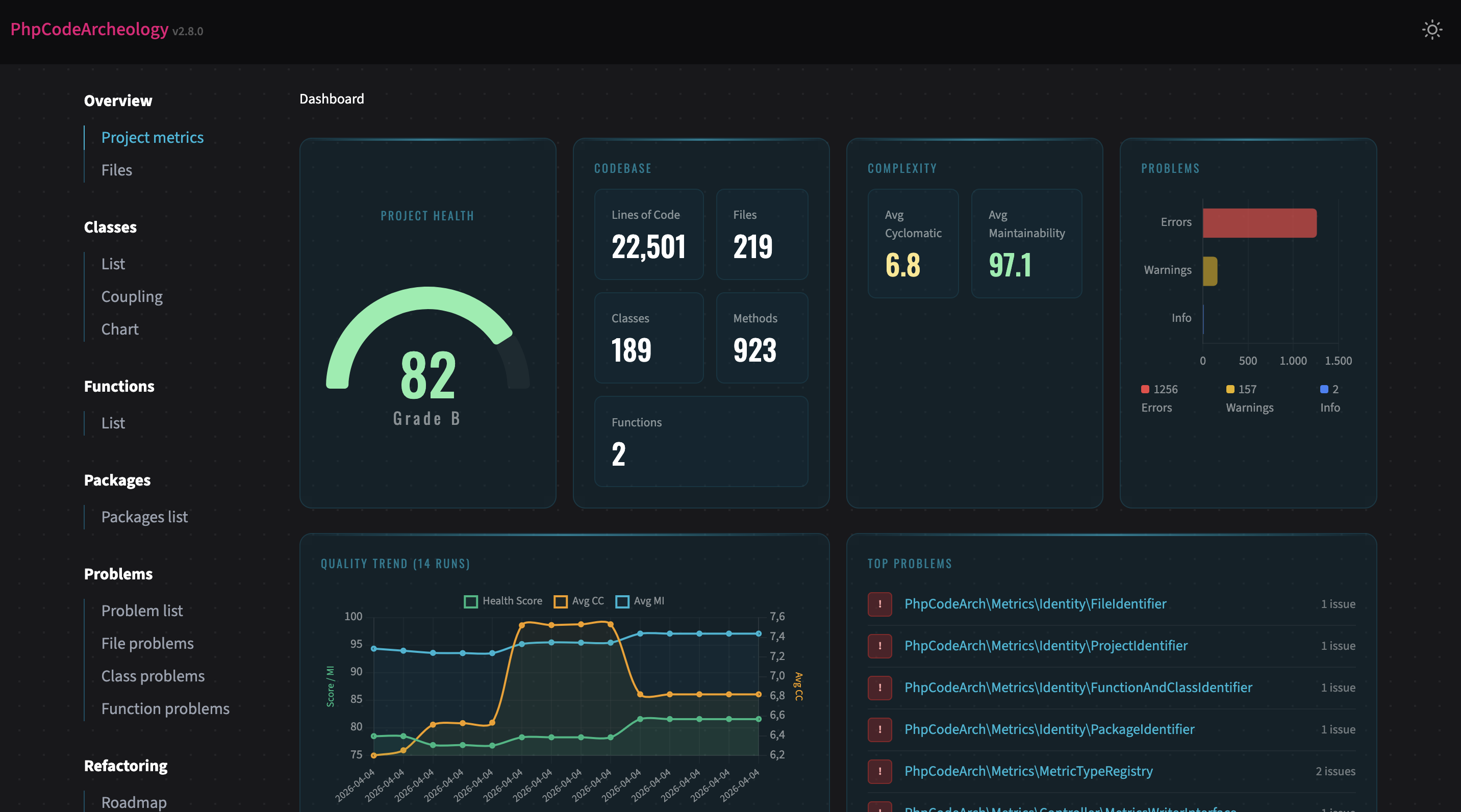
Von dort aus gehe ich in die Probleme. Drei Dinge schaue ich mir zuerst an: God Classes, Coupling und Complexity. Das sind die Klassiker. Und meistens auch die, die den größten Hebel haben.
Aber der eigentlich interessante Moment kommt, wenn ich die Git-Analyse und den Knowledge Graph öffne.
Der blinde Fleck
Bei einem Projekt, das ich übernommen habe, hatten wir vorher im Team besprochen, wo wir die meisten Probleme erwarten. Jeder hatte seine Vermutung, jeder kannte “die eine Stelle” im Code.
Die Analyse hat dann eine ganz andere Klasse nach oben gespült. Eine, die laut Git-Verlauf extrem häufig angepasst wurde und gleichzeitig eine sehr hohe Komplexität hatte - ein klassischer Hotspot. Das Ding war den Ursprungsentwicklern so sehr in Fleisch und Blut übergegangen, dass es niemand mehr als Problem wahrgenommen hat.
Genau das meine ich: Ohne Messung verlässt du dich auf Bauchgefühl. Und Bauchgefühl hat blinde Flecken.
Refactoring priorisieren
PhpCodeArcheology hat eine Hotspot-Erkennung. Ich nenne sie intern die Refactoring-Hitliste. Sie zeigt dir Dateien mit hoher Änderungsfrequenz und hoher Komplexität. Das sind die Stellen, die am meisten Aufmerksamkeit verdienen, weil sie häufig angefasst werden und gleichzeitig schwer zu verstehen sind.
In dem Fall oben haben wir mit genau diesem Hotspot begonnen. Nicht weil er der offensichtlichste war, sondern weil die Daten klar gesagt haben: Hier liegt der größte Hebel.
Erfolg messen
Nach jedem Refactoring lasse ich das Tool erneut laufen. Nicht erst am Ende, sondern nach einzelnen Schritten, um direkt zu sehen, ob es geholfen hat. Dafür nutze ich entweder den normalen Trend-Verlauf oder den compare-Command:
./vendor/bin/phpcodearcheology compare baseline.jsonDie kurzen Feedback-Loops sind wichtig. Du willst nicht drei Wochen refactoren und dann feststellen, dass sich die Metriken nicht bewegt haben.
Wenn Refactoring die Zahlen verschlechtert
Das passiert. Und das ist okay.
Wenn du eine God Class aufteilst, steigt die Anzahl der Klassen. Damit entstehen neue Abhängigkeiten, das Coupling kann kurzfristig steigen. Das bedeutet nicht, dass das Refactoring falsch war. Du musst die Zahlen im Kontext lesen.
Und manchmal muss man auch einfach sagen: Was dieser Code tut, ist komplex. Die Komplexität steckt im Usecase, nicht im schlechten Design. Dann kannst du die Complexity nicht aus dem Code ziehen, egal wie oft du refactorst.
PhpCodeArcheology ist ein Werkzeug, kein Richter. Das Ziel ist nicht, alles auf Grün zu bringen auf Teufel komm raus. Das Ziel ist, zu verstehen.
Neuentwicklungen: Von Tag 1 an messen
Beim zweiten Use Case geht es nicht um Archäologie, sondern um Prävention. Ich schalte PhpCodeArcheology in jedem neuen Projekt ab Tag 1 ein.
Klar, man kann über Git immer alte Stände auschecken und nachträglich prüfen. Aber ich habe lieber eine solide History von Anfang an. Wenn du nach sechs Monaten Entwicklung zum ersten Mal misst, fehlt dir der Verlauf. Du siehst eine Momentaufnahme, aber nicht den Trend.
Der Workflow
Immer wenn ein Feature fertig ist, lasse ich das Tool laufen. Manchmal zwischendurch mit --quick für den schnellen Überblick im Terminal:
./vendor/bin/phpcodearcheology --quick src/Regelmäßig dann den vollen HTML-Report. Für tiefere Analysen nutze ich auch den MCP-Server - dazu kommt ein eigener Artikel.
Dependency Circles im Team
Während einer Teamarbeit an einem neuen Projekt hat PhpCodeArcheology einen Dependency Circle aufgedeckt, den wir sonst nicht so schnell gefunden hätten. Wenn mehrere Entwickler parallel an verschiedenen Features arbeiten, können solche zirkulären Abhängigkeiten leicht entstehen. Und sie werden erst zum echten Problem, wenn du sie nicht früh erkennst.

Der Knowledge Graph macht solche Strukturen sichtbar. Welche Klasse hat wie viele Verbindungen? Wo sitzen die zentralen Knoten? Gibt es Zyklen? Das siehst du auf einen Blick.
Was ich über meinen eigenen Code gelernt habe
Seit ich das Tool regelmäßig nutze, ist mir eine Sache klar geworden: Die Planungsphase kann ruhig auch mal etwas länger sein. :)
Im Ernst: Wenn du von Anfang an misst, siehst du, wie sich Architekturentscheidungen auswirken. Nicht in der Theorie, sondern in Zahlen. Und das verändert, wie du planst.
Metriken, die überrascht haben
Cyclomatic Complexity: Damit muss man vorsichtig sein. Eine hohe CC ist nicht automatisch ein Problem. Manchmal ist der Code komplex, weil der Usecase komplex ist. Manchmal ist es aber auch unnötige Komplexität. Das muss dann die Erfahrung entscheiden.
LCOM (Lack of Cohesion of Methods): Die habe ich anfangs unterschätzt. Ich brauchte etwas, um hinter die Metrik zu kommen. Aber jetzt will ich sie nicht mehr missen. LCOM zeigt dir, ob eine Klasse wirklich eine Einheit bildet oder eigentlich mehrere Verantwortlichkeiten in sich trägt. Wenn der Wert hoch ist, hast du oft eine Klasse, die aufgeteilt werden sollte - und das bestätigt sich in der Praxis fast immer.
Fazit
Ich nutze PhpCodeArcheology nicht, weil ich es gebaut habe. Ich habe es gebaut, weil ich es brauchte.
Ob Legacy-Bewertung oder Neuentwicklung: Das Tool gibt mir den Überblick, den ich ohne Messung nicht hätte. Es ersetzt weder Erfahrung noch Verstand - aber es gibt beiden eine solide Grundlage.
Du kannst deinen Code kennen. Aber du kannst ihn auch messen. Und wenn Bauchgefühl und Daten sich widersprechen, hat meistens die Messung recht.
PhpCodeArcheology ist Open Source und kostenlos. Hier geht’s zum GitHub-Repo - Feedback ist willkommen.